Introduction
In the world of tech and business, using data smartly is super important for making good decisions and coming up with new ideas. The Data Science Lifecycle is like a step-by-step plan for creating and keeping up with data-based solutions. This article explains the jobs of different experts, like domain experts and data scientists, in each step. It's a teamwork journey from finding issues to collecting, analyzing, and using data. Knowing this cycle is not just for pros but also for businesses that want to be smart and successful using data.
What is the Data Science Lifecycle?
A data science life cycle is like a step-by-step plan for making and keeping up with data projects. Even though not all projects are the same, they usually go through common steps like using machine learning and statistics to make better predictions. The main stages include getting data, getting it ready, cleaning it up, creating models, checking how good they are, and more. People in the data science community often call this overall process the "Cross Industry Standard Process for Data Mining."
Data Science Lifecycle Diagram
The life cycle of data science contains the following steps:
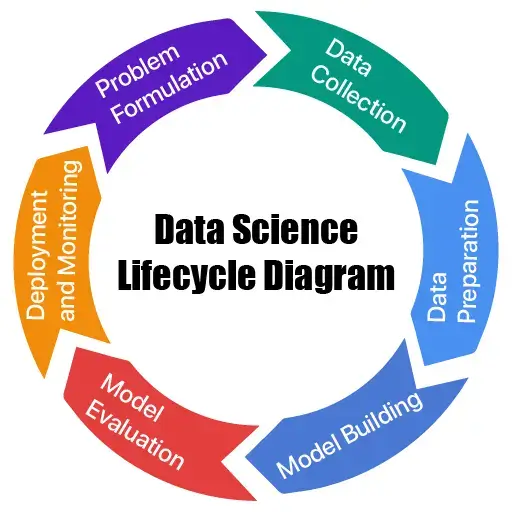
- Problem Formulation
- Data Collection
- Data Preparation
- Model Building
- Model Evaluation
- Deployment and Monitoring
Who Are Involved in The Projects?
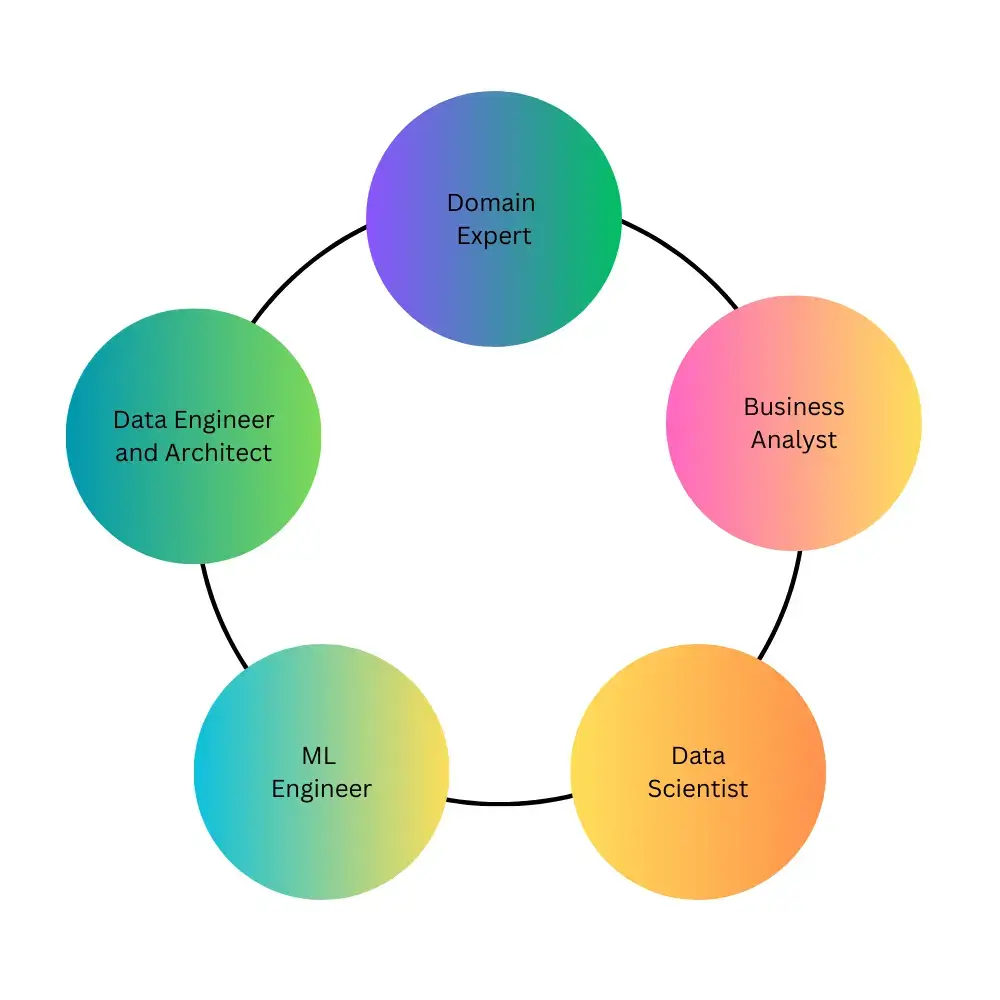
Domain Expert
Data science projects help in different areas like Banking, Healthcare, and the Petroleum industry. In The Data Science lifecycle, A domain expert is someone who knows a lot about a specific field and has hands-on experience in it.
Business analyst
A business analyst is important for figuring out what a business needs in a certain area. They help come up with the right solution and set a timeline for making it happen.
Data Scientist
A data scientist is someone good at data projects. They solve problems by determining the necessary data to achieve the desired result.
Machine Learning Engineer
A machine learning engineer helps us choose the best model to get the result we want and creates a solution to make sure we get the right and necessary outcomes.
Data Engineer and Architect
In the Data Science lifecycle, Data architects and data engineers are experts in organizing data. They simplify understanding by creating visualizations and ensuring efficient storage and retrieval of data.
Learners Also Read:- Data Science Tools and Services for Profitable Decision-Making
Data Science Life Cycle Steps
The data science lifecycle involves several key steps that data scientists follow to extract valuable insights from data.
- Problem identification: Finding the problem is really important in a Data Science project. It means knowing how Data Science can help in a specific area and figuring out important tasks. The key people doing this are domain experts and Data Scientists. A domain expert knows a lot about the area and the exact problem. At the same time, the Data Scientist understands the area and helps find problems and solutions.
- Business Understanding: Understanding what the customer wants for their business is called Business Understanding. It could be predictions, better sales, less loss, or improving processes, and these wishes shape the business goals. In the business understanding phase, we take two important steps:
- Key Performance Indicator (KPI): In data science projects, Key Performance Indicators (KPIs) decide if the project is successful. The customer and the data science team work together to set business goals. These goals, based on business needs, help achieve objectives like doubling clients while using resources wisely. Choosing KPIs is crucial for cost-effective solutions.
- Service Level Agreement (SLA): In Data science technology, Once success metrics are decided, it's crucial to set rules in the Service Level Agreement (SLA) based on business needs. For example, if it's an airline reservation system, the SLA might require handling 1000 users simultaneously. Meeting these SLA requirements is vital for the project to move forward.
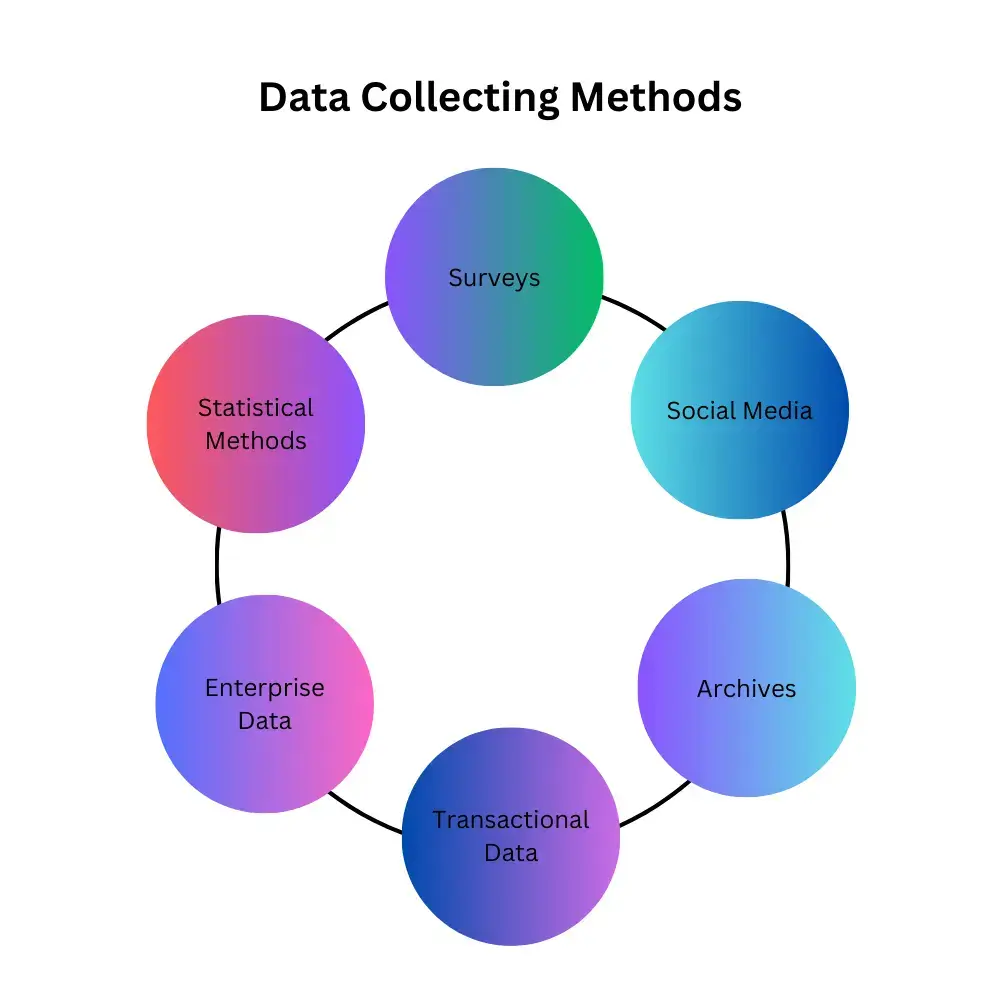
- Collecting Data: Collecting data is important because it's the foundation for reaching the goals of the business. The data comes into the system in different ways, as shown in Figure 2.
To gather important information, businesses often use surveys, recording data from different areas in software systems. Historical data from archives and daily transactions are crucial for understanding the business, and statistical methods help extract vital information, highlighting the importance of effective data collection.
- Pre-processing Data: Data is gathered from different places in various formats and then converted into a single format. This processed data is stored in a data warehouse using a crucial process called Extract, Transform, and Load (ETL), managed by a key figure, the data architect.
- Analyzing Data: Once the data is in the right format, the next crucial step is understanding it through Exploratory Data Analysis (EDA). A data engineer, important in EDA, uses statistical functions to find important features. Careful analysis reveals crucial insights and tools like Tableau and PowerBI help visualize the data for better understanding. Knowing Data Science with Python and R is essential for effective EDA on any type of data.
- Data Modelling: Once we understand the data, the next important step of the Data Science Lifecycle is data modeling, where we keep the important parts in the dataset to make the data better. We decide how to model the data and choose tasks like classification or regression based on what the business needs. Machine Learning engineers use different methods to get the output, testing models on dummy data similar to the real dataset.
- Model Evolution/monitoring: Deciding the best way to model data is very important. We test the model with real data in the model evaluation and monitoring phase. If there's only a small amount of data, we closely watch the output for improvements. Changes in the data during testing can greatly affect the results. During model evaluation, two crucial phases come into play:
- Data Drift Analysis: Changes in input data are referred to as data drift, a common phenomenon in data science due to varying situations. Analyzing this change is known as Data Drift Analysis. The model's accuracy depends on its ability to handle data drift, which occurs primarily due to changes in the statistical properties of data.
- Model Drift Analysis: Once you've looked at and understood the data, the next important step is data modeling. This means deciding how to organize the data and what tasks to focus on, like classification or regression, based on the business needs. There are different ways to model the data, and Machine Learning engineers use various methods to generate results.
- Model Training: In the final stages, once the task, model, and data drift analysis are settled, the crucial step is to train the model. This training, done in phases, fine-tunes important parameters for accurate output. In the production phase, we expose the model to actual data and continuously monitor the output.
- Model Deployment: Once the model is trained with real data and adjusted for accuracy, it's time to deploy it. The model starts processing real-time data, and deployment can be as a web service or embedded in edge or mobile applications. This step is critical as it exposes the model to the real world in the data science lifecycle.
- Driving insights and generating BI reports: In the real world, after deploying the model, the next step is to see how it works. The model provides insights for important business decisions, linked directly to business goals. Teams create reports to assess the business's performance and whether it meets key goals.
- Taking a decision based on insight: Absolutely! Executing each step accurately in data science renders the generated reports crucial for making key decisions in the organization. The insights gained help in strategic decision-making, like predicting the need for raw materials in advance, contributing to business growth, and better revenue generation.
Conclusion
In conclusion, The Data Science Lifecycle is like a roadmap for using data in tech and business. It involves experts like domain specialists, analysts, data scientists, and engineers in different stages, guiding the journey from identifying problems to using data for smart decisions. It's crucial for both professionals and businesses aiming for success. Following each step carefully allows organizations to use data effectively, making smart decisions for growth.
Frequently Asked Questions
Q1.What are the 6 steps of data science lifecycle?
Ans. The six steps of the data science cycle are Problem Definition, Data Collection, Data Preparation, Modeling, Evaluation, and Deployment.
Q2.Who is the father of data science?
Ans.The name "data science" was coined by William S. Cleveland in 2001, but the field's development involved contributions from various pioneers like John W. Tukey. There isn't a single "father" of data science; it emerged through collaborative efforts and insights from multiple individuals.
Q3.What is data science in simple words?
Ans.Data science is a way of using science and computer skills to understand and make decisions from the information we get from different sources. It helps us find useful things in data and solve problems.
